利用 Chrome DevTools 把微博打包成 zip 文件
date
Feb 10, 2020
note
slug
weibo-zip
type
Post
status
Published
tags
技术
Web
summary
过去在微博遇到许多带来思考与快乐的内容,但常常因为时间太久远,回看收藏链接往往返回的是404,记忆也随之变成了一个个空洞。脑洞打开,是不是可以把一条微博涉及到的各种文件一键打包下载,在本地阅读呢,就像 docx 文档格式一样。
过去在微博遇到许多带来思考与快乐的内容,但常常因为时间太久远,回看收藏链接往往返回的是404,记忆也随之变成了一个个空洞。脑洞打开,是不是可以把一条微博涉及到的各种文件一键打包下载,在本地阅读呢,就像 docx 文档格式一样。
技术方案
从尽可能简单的角度解决问题的角度出发,能在浏览器端完成的话最好,不需要依赖什么脚本和平台,额外花时间去梳理各种业务逻辑相关的琐事。从此出发,在数据来源方面,选择更简单的手机版;保存数据,优先考虑在浏览器端用文件相关的 API 实现。
理论上来说,文件的本质是一系列二进制数据集合,HTML5 FileAPI 提供了处理二进制数据对象的 Blob。在浏览器环境中字符串可以构造成 Blob,微博中涉及到的图片和视频文件的数据也通过 Blob 的方式处理。
有了 Blob 这一层抽象,文件打包压缩的需求,也用 Blob 的方式去实现的话会更自然一些。寻找已有的解决方案,发现 JSZip,它支持创建 zip 的文件,在输入输出的表达上支持包括 Blob 在内的多种格式,也支持 ArrayBuffer, Base64, 字节数组等等方式的表达,省下不少自己处理的功夫。
文件下载方面,可以用
URL.createObjectURL 基于 Blob 创建一个 Object URL,然后创建一个 <a> 元素,触发 click 事件下载,得到最终的文件。把数据源与保存的方式都理清楚,大致有了一个流程,就可以动手了。
在运行环境方面,不需要额外安装什么,只需要一个 DevTools 即可,开发者工具提供了 Snippets(代码片段)功能,可以直接在里面写那些需要在注入到页面的代码片段然后运行,很方便。参考这篇文章
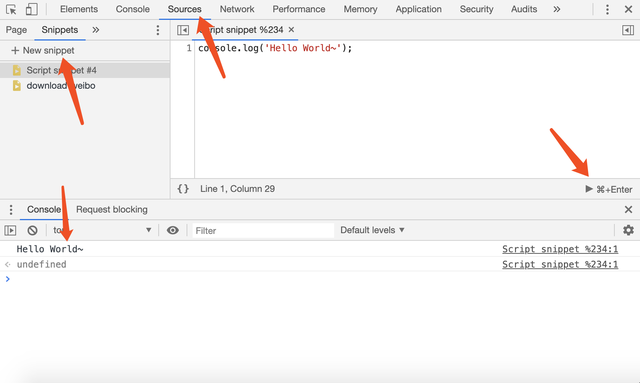
下面是实现的思路:
数据的获取
1. 基础数据
微博移动版为减少请求,会在 HTML 输出该条微博的信息,在
$render_data.status 里。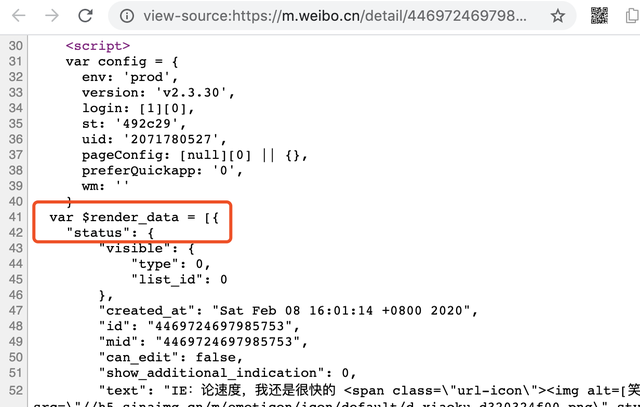
2. 评论与转发
直接上
Networks 面板,定位到相关的 HTTP 请求,然后右键 Copy as fetch,即可得到基于 fetch 的请求代码。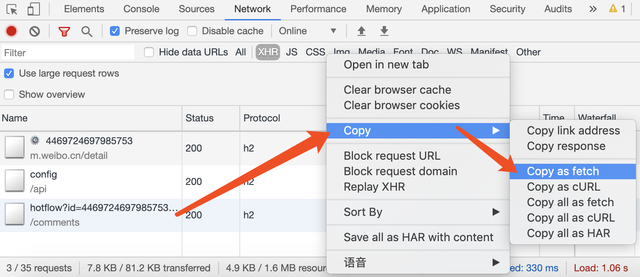
把代码梳理之后抽象成如下函数:
async function fetchWeibo(url) { return await fetch( url, { credentials: "include", headers: { accept: "application/json, text/plain, */*", "accept-language": "zh-CN,zh;q=0.9,en;q=0.8", "mweibo-pwa": "1", "sec-fetch-mode": "cors", "sec-fetch-site": "same-origin", "x-requested-with": "XMLHttpRequest", "x-xsrf-token": getCookie('XSRF-TOKEN') }, referrer: `https://m.weibo.cn/status/${$render_data.status.bid}`, referrerPolicy: "no-referrer-when-downgrade", body: null, method: "GET", mode: "cors" } ).then(r => r.json()); function getCookie(key) { return document.cookie .split("; ") .map(item => item.split("=")) .reduce((accu, curr) => { accu[curr[0]] = curr[1]; return accu; }, {})[key]; } } async function fetchWeiboComments(max_id = 0, max_id_type = 0) { return await fetchWeibo( `https://m.weibo.cn/comments/hotflow?id=${$render_data.status.id}&mid=${$render_data.status.mid}&max_id=${max_id}&max_id_type=${max_id_type}` ); }
由于分页的关系,实际抓取时需要传最后一条评论的 id 才可获取下一页,考虑到热门的微博评论和转发太多,直接抓取并不现实,且会给服务器带来额外的压力,微博的 robots.txt 不给我们这么干,本着学习研究的初心,这里抓两页就收工。
评论与转发也同理,这里就不贴了。
3. 图片与视频等资源的获取
在
$render_data.status.pics 我们可得到微博配图的 URL,$render_data.status.page_info.media_info,可以得到视频的 URL。遍历的时候 fetch ,相应请求的时候调用 response.blob() 让这个请求返回对应的 Blob。但这里有个问题,微博配图和视频都不是同一个域名之下的资源,会受到 CORS 机制 的限制,微博返回的请求也没有对应的 CORS 头部,自然会被拦截。
为了解决跨域拦截问题,找到一个代理工具 Cors Anywhere,它提供一个 HTTP 服务,只需要在目标 URL 前加入它的地址,按原样请求原始地址,并在返回的响应头中加上对应的
Access-Control-Allow-Origin:。抓取的请求可以包装为一个函数,
corsProxyServer 即 Cors Anywhere 的地址:const corsProxyServer = ''; async function fetchBlob(url) { return await fetch(`${corsProxyServer}${url}`, { credentials: "omit", referrer: `https://m.weibo.cn/detail/${$render_data.status.id}`, referrerPolicy: "no-referrer-when-downgrade", body: null, method: "GET", mode: "cors" }).then(r => r.blob()); }
项目主页提供了一个运行在 Heroku 的例子,一般图片都比较大,测试发现下载速度感人,不如在本地搭建一个。
搭建很简单,
git clone, npm install 运行一把梭,但是就有一个问题,本地运行的服务开放的端口是 http 的,在 https 的站点对一个 http 的站点发 XHR 会被拦截,需要考虑域名与 https 证书的配置,带来的则是一堆繁琐的事情。我只是想跑一个小服务,能不能简单点?当然能!这时候祭出一大神器:whistle。
whistle 是一个基于 Node 实现的 Web 请求调试代理工具,支持 HTTP, HTTPS, WebSocket 的请求的修改和转发,通过编写 whistle 配置,可以实现各种非常灵活的功能。
一条 whistle 配置解决一切蛋疼:
cors.proxy 127.0.0.1:8888
打包压缩
(我只是一个调包侠
const zip = new JSZip(); zip.file("content.json", statusDataBlob); zip.file("interaction.json", interactionDataBlob); const picsFolder = zip.folder("pics"); imgBlobList.forEach(item => { const { pid, smBlob, lgBlob } = item; picsFolder.file(`${pid}.${smBlob.type.split('/')[1]}`, smBlob); picsFolder.file(`${pid}.large.${lgBlob.type.split('/')[1]}`, lgBlob); }); const videosFolder = zip.folder("videos"); videoBlobList.forEach(item => { const { bid, videoBlob, videoHDBlob } = item; videosFolder.file(`video-${bid}.${videoBlob.type.split('/')[1]}`, videoBlob); videosFolder.file(`video-${bid}-hd.${videoHDBlob.type.split('/')[1]}`, videoHDBlob); }); const finalResultBlob = await zip.generateAsync({ type: "blob", });
下载
开头已介绍过思路,直接上代码:
const a = document.createElement('a'); a.download = `weibo-${$render_data.status.bid}-${dateStr}.zip`; a.href = URL.createObjectURL(finalResultBlob); a.click();
查看器的设计
单纯实现下载并不够,所以特地花了半天时间用
TypeScript 基于 React 做了个查看器,用 JSZip 解压,然后再生成 Object URL 直接展示。做这个查看器的时候尝试了 Parcel,做一些小的项目的确是很舒心,不会在一开始的时候就陷入各种 Webpack 配置的泥潭无法自拔。唯一需要留意的是
tsconfig.json 需要手动配置一下,不然在写 .tsx 组件的时候 VSCode 的代码提示会有问题。写完连着下载代码一块传到了 Github,起了个名儿叫
weibo-zip,地址:zgq354/weibo-zip查看器的页面也放了一个,若你有兴趣可以体验体验:https://zgq354.github.io/weibo-zip/
后来上传了一些例子,parcel 默认没有直接拷贝文件的操作,搜索一番发现了 parcel-plugin-asset-copier。
总结
关于控制台写脚本爬网页数据
优势:
- 只要有浏览器就能跑
- 不用考虑模拟登录等琐碎问题,直接拥有登录态
- 可以减少环境差异带来的坑:比如说这里遇到了一处微博返回的 JSON 的 Date 字符串在 Python 会出现解析失败的问题,但在 JS 里面
new Date('xxx')是正常返回的。
劣势:
- CORS 跨域问题,导致不能拿来就用
- 请求有并发限制
综上,它比较适合简单处理一些小数据的抓取和处理。本来选择 Console 实现就是看准了它的便利性,但也因为需要手动解决跨域的问题,直接扼杀了它的实用性,所以只能算是个折腾玩具了哈哈~
React 有 Create React App 可以快速搭项目,但有时候并不想限制在这一套体系下,相比于一切都以 js 为中心的 Webpack,Parcel 会更自然一些。
在写一些自己玩的小东西的时候,用一些类似 Parcel 的工具可以快速出活,关注点也多放在要解决的问题上。